最大匹配算法与隐马尔科夫模型|中文分词|NLP
简单谈谈两种算法在中文分词中的实现与比较。
季更博主居然更博啦!
上学期上了自然语言理解这门课,最后两个实验一个是做写词机器人,另一个是中文分词。前者用了LSTM模型,虽参考了MC胖虎但效果并不好,就不多说了。
本文就对中文分词的两种算法做个总结,分别是最大匹配算法和隐马尔科夫模型。
最大匹配算法
主要思想
最大匹配算法分为正向和逆向两种。区别主要在于对句子的切分方向。前者从前向后,后者从后向前。
总的来讲,基于现有的词典,设置最大分词长度,从前向后(或从后向前)切分句子。见流程图: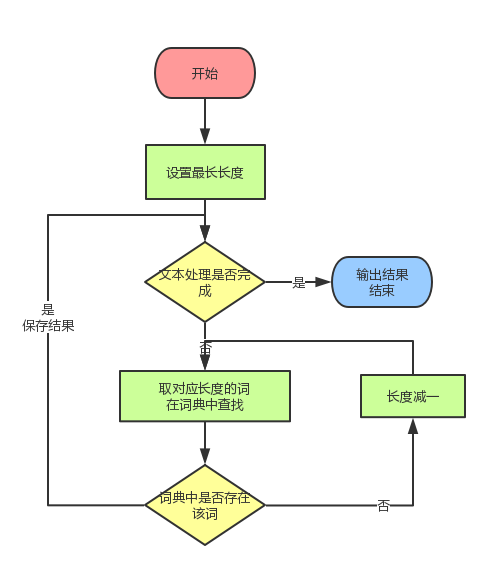
接着来谈谈正向和逆向的区别
对中文分词而言,一般逆向比正向效果好。
但两种都有其局限性,于是有了双向匹配算法:分别进行正向和逆向切分,根据一定原则选择合适的切分方法。
原则(参考中文分词基础-新浪博客):
1.颗粒度越大越好:单词的字数越多,所能表示的含义越确切。如:“公安局长”可以分为“公安 局长”、“公安局长”、“公安局长”都算对,但是要用于语义分析,则“公安局长”的分词结果最好(当然前提是所使用的词典中有这个词)
2.非字典词和单字字典词越少越好
3.总体词数越少越好
我实现了逆向匹配算法,代码比较简单,需要的话请留言。
隐马尔可夫模型
隐马尔科夫模型(HMM)是一种统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。
它是一个五元组:状态值集合,观察值集合,转移概率矩阵,发射概率矩阵和初始状态分布。
在中文分词问题中,
状态值集合:为(B,M,E,S),分别表示词首、词中、词尾和单独成词。
观察值集合:待处理文本。
初始状态分布:语料库中每个句子第一个字所处状态的概率。
转移概率矩阵:某个字所处的某状态转移到下一个字对应的状态的概率。
发射概率矩阵:表示语料库中所有字对应某个状态的概率。
同时,使用Viterbi算法求解最优路径,即得到分词结果。
Viterbi算法是一种动态规划算法,它的主要思路是:
- 根据待处理文本s的第一个字,初始化weight[4][N](N为s的长度,weight[4][N]表示4行N列的数组)。具体而言,weight[m][n]的含义是第n个字对应状态m的概率。
- 同时,为求解最优路径,我们再设置一个**path[4][n]**(N为s的长度,path[4][N]表示4行N列的数组)。具体而言,path[m][n]的含义是当前字的weight[m][n]取最大时,它的前一个字的状态。path数组为我们后续分词提供便捷。
由第一个字的概率向后计算得到每一个字对应状态下的概率即weight[m][k]。
计算过程代码如下(参考HMM用于中文分词-简书):
1 | //i表示句子的第i个字 |
Points
- 需要词典和语料进行训练,是有监督的学习
- 对于词典中没有的词,在对文本进行分词时的计算要注意。
隐马尔可夫模型的其他应用
语音识别等
一些补充
读了吴军的《数学之美》,书中的第五章就是讲的隐马尔科夫模型。Vertibi算法是一个解码的功能,在分词中也就是求得weight矩阵并逆向分析得到分词结果(即Path)。
他在书里的补充部分还提到了鲍姆-韦尔奇算法,用来计算模型参数,在我们这个分词应用中还没有用上,这个我也没有太弄懂。
最大匹配算法与隐马尔可夫模型比较
前者优点在于易于实现,而对于一些未登录词的识别效果不佳。
后者优点在于能较好地识别未登录词,但是计算量大。
两个正好相反~
下面是个演示,可以看出对一些奇怪的词语,隐马尔科夫模型分词效果会比较好。
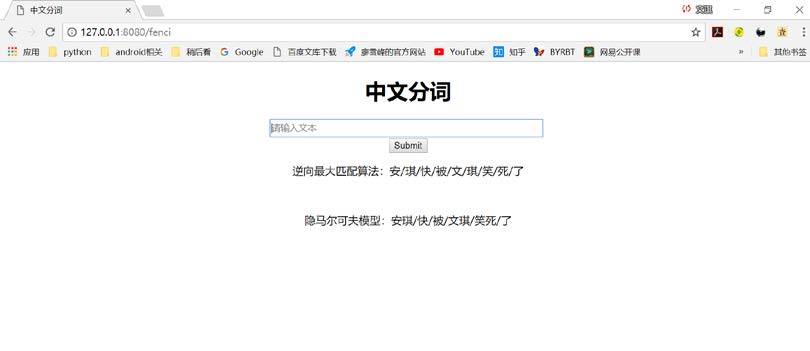
One More Thing
- Python中文读的问题。字典是通过老师给的新闻语料创建的。涉及一个读入问题和一个除杂问题。我觉得中文处理还挺麻烦的。
一个是文件转为无BOM的utf-8,一个是中文字符范围,一个是正则表达式。
(1)转为无BOM的UTF-8用NotePad就可以。
(2)网上就能查到
(3)利用正则和中文字符范围可以除杂
后记
时隔不知道几个月,再把这篇草稿翻出来。很多知识忘了,又重新学了一遍,算法还是得常看呐。旧文凑更啦~ o(* ̄▽ ̄*)ブ
深度学习,神经网络这一类的东西都给我一种不靠谱的感觉。再比如说,模型比较起来结果很明显的隐马尔可夫模型会好一些,但是为什么呢?
我也怀疑是因为我自己没有动手搭建过的原因,给我一种很玄幻的感觉。
Anyway,那么下一个目标是自己动手搭建神经网络。